Bad data - it's everywhere and a common problem is badly formatted dates. "conversion failed when converting date and/or time from character string" is the message returned in such situations. It's not unique to SQL and will be seen in other languages such as Python, C#, Java and others. In this post, we look at the why and how you can fix it. Getting to the bottom of … [Read more...] about How to fix “conversion failed when converting date and/or time from character string”
Using SQL GROUPING SETS for Multiple GROUP BY Queries in a Single Query
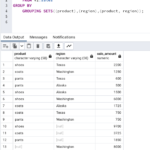
SQL GROUPING SETS is a feature of the SQL language that allows you to specify multiple group by sets in a single query. The best way to demonstrate this is with code and examples. So imagine you have table of sales data which contained the following fields: product region sale_amount A visual of this would look like: Now say you had a requirement to … [Read more...] about Using SQL GROUPING SETS for Multiple GROUP BY Queries in a Single Query
How to Setup MySQL Master Master Replication
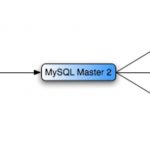
MySQL master master replication, also known as "mysql chained replication", "multi master replication or "mysql daisy chaining replication" is an extension of mysql replication allowing the creation of multiple master servers that can then be masters of multiple slaves. In this post, I demonstrate how to setup mysql master master replication. In a multi master mysql … [Read more...] about How to Setup MySQL Master Master Replication
How To Use SQL to Convert a STRING to an INT
Using SQL to convert a string to an int is used in a variety of situations. You may have text data that you cannot alter at the source and you need to get some accurate answers from it. You may also have text data that you want to insert to an integer column. There could be other reasons too. There is an easy solution to this and I will show you examples in both SQL Server … [Read more...] about How To Use SQL to Convert a STRING to an INT
How to set up MySQL Replication Tutorial
One may setup MySQL replication typically either to scale out, facilitate reporting or to provide backups of MySQL databases. I wrote a post about this before. The whole process relies on binary logs which are output to a location on the master server and read in by the slave. This post is a MySQL replication tutorial. I am going to setup MySQL replication involving two My … [Read more...] about How to set up MySQL Replication Tutorial